
Birth Certificate
This section describes how to build your custom OCR API to extract data from Birth Certificates using the API Builder. A birth certificate is a vital record that documents the birth of a person.
Prerequisites
You’ll need at least 20 Birth Certificate images or pdfs to train your OCR.
Define Your Birth Certificate Use Case
Using the Birth certificate below, we’re going to define the fields we want to extract from it.

- First name: The first name of the birth certificate holder
- Last Name: The last name of the birth certificate holder
- Birth Date: The date of birth of the birth certificate holder
- City of Birth: The city of birth of the birth certificate holder
- Certificate Number: The certificate Number
That’s it for this example. Feel free to add any other relevant data that fits your requirement.
Deploy Your API
Once you have defined the list of fields you want to extract from your Birth certificate, head over to the platform and follow these steps:
-
Click on the Create a new API button on the right.
-
Next, fill in the basic information about the API you want to create as seen below.

-
Click on the Next button. The following page allows you to define and add your data model.
Define Your Model
There are two ways to add fields to your data model.
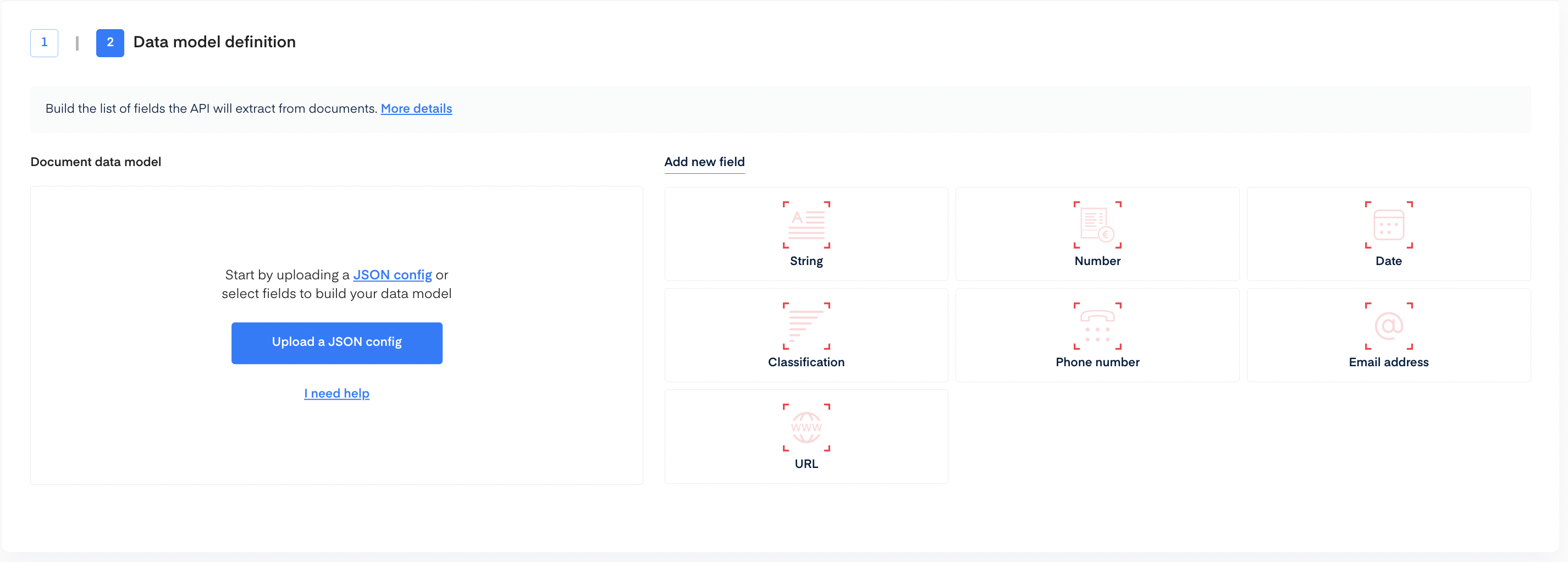
Upload a JSON Config
To add data fields using JSON config upload.
- Copy the following JSON into a file
{
"problem_type": {
"classificator": { "features": [], "features_name": [] },
"selector": {
"features": [
{
"cfg": { "filter": { "alpha": -1, "numeric": 0 } },
"handwritten": false,
"name": "first_name",
"public_name": "First name",
"semantics": "word"
},
{
"cfg": { "filter": { "alpha": -1, "numeric": 0 } },
"handwritten": false,
"name": "last_name",
"public_name": "Last Name",
"semantics": "word"
},
{
"cfg": { "filter": { "convention": "US" } },
"handwritten": false,
"name": "birth_date",
"public_name": "Birth Date",
"semantics": "date"
},
{
"cfg": { "filter": { "alpha": -1, "numeric": 0 } },
"handwritten": false,
"name": "city_of_birth",
"public_name": "City of Birth",
"semantics": "word"
},
{
"cfg": { "filter": { "is_integer": -1 } },
"handwritten": false,
"name": "certificate_number",
"public_name": "Certificate Number",
"semantics": "amount"
}
],
"features_name": [
"first_name",
"last_name",
"birth_date",
"city_of_birth",
"certificate_number"
]
}
}
}
- Click on Upload a json config
- The data model will be automatically filled.
- Click on Create API at the bottom of the screen.
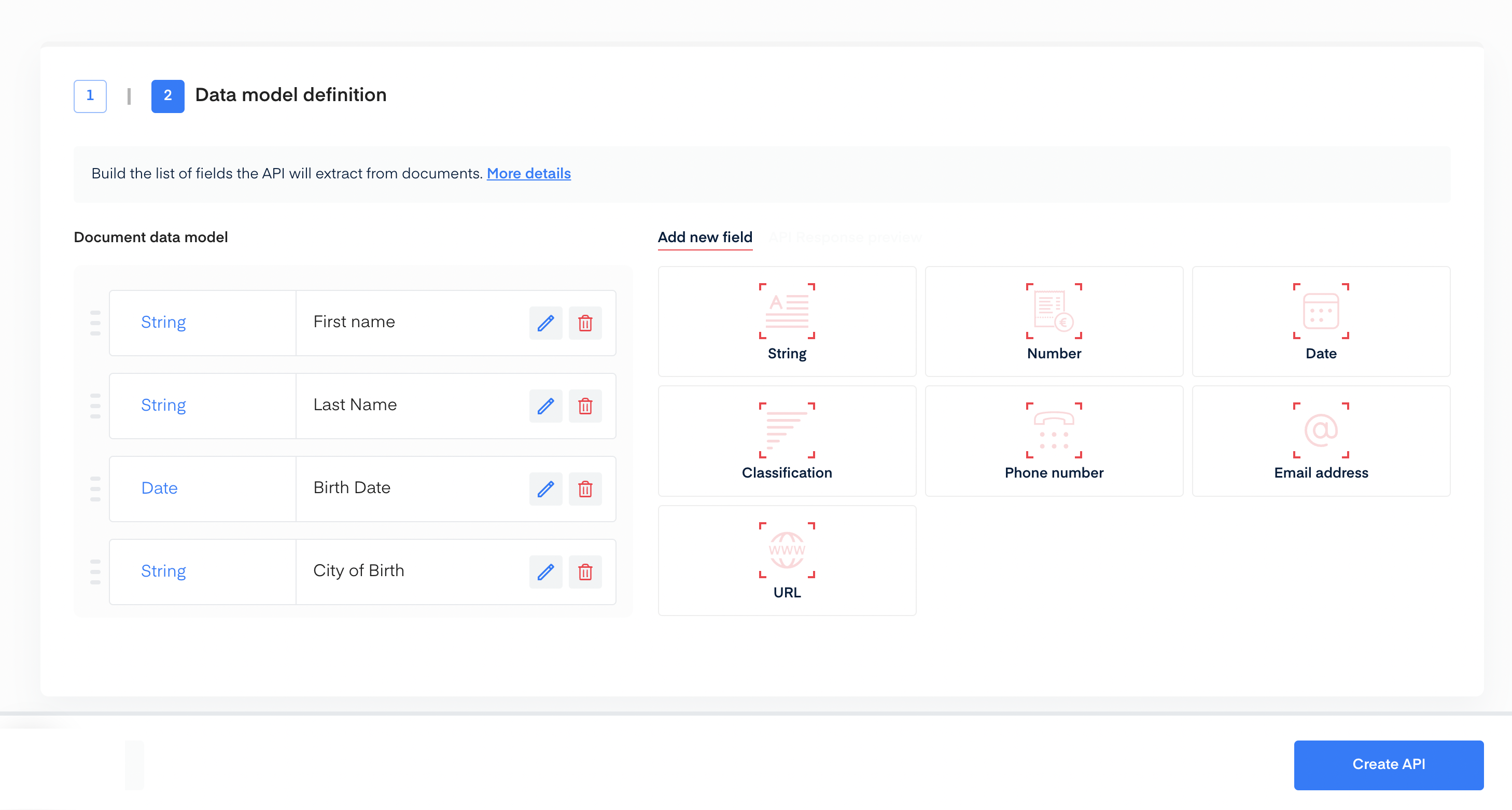
Manually Add Data
Using the interface, you can manually add each field for the data you are extracting. In our example, here are the different field configurations we used:
- First name: type String that never contains numeric characters.
- Last Name: type String that never contains numeric characters.
- Birth Date: type Date with US format.
- City of Birth: type String that never contains numeric characters.
- Certificate Number: type Number without specifications.
Once you’re done setting up your data model, click the Create API button at the bottom of the screen.
Train Your Birth Certificate OCR
You’re all set! Now it's time to train your Birth certificate deep learning model in the Training section of our API.
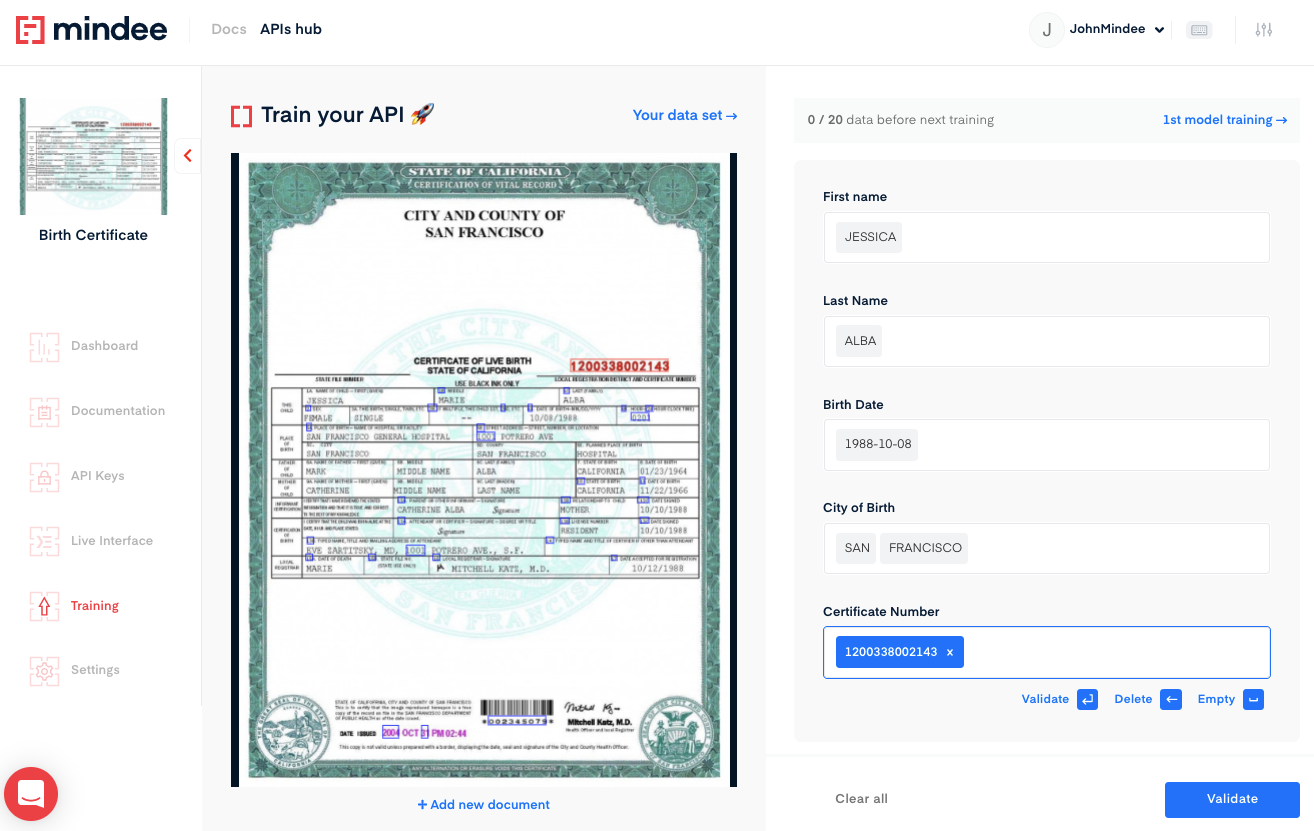
- Upload one file at a time or a zip bundle of many files.
- Click on the field input on the right, and the blue box on the left highlights all the corresponding field candidates in the document.
- Next, click on the validate arrow for all the field inputs.
- Once you have selected the proper box(es) for each of your fields as displayed on the right-hand side, click on the validate button located at the right-side bottom to send an annotation for the model you have created.
- Repeat this process until you have trained 20 documents to create a trained model.
To get more information about the training phase, please refer to the Getting Started tutorial.
Questions?
![]() Join our Slack
Join our Slack
Updated over 1 year ago