
Financial document OCR
Keep track of the changes and updates for the Financial document OCR API.
Version 1
⚡️ Features and Changes (April 28th, 2025)
- ✨ ⚡ Expand the granularity of the
categoryandsub_categoryoutput.- ✨ New categories:
energy,shopping,software - ✨ New sub-categories:
fooddelivery(Deliveroo, UberEats...)
transportpublic(tram, rer, metro, underground, Bus...)car_rentalmicro_mobility(Short-term rentals, like scooters and bikes.. For further information, you can consult https://en.wikipedia.org/wiki/Micromobility)
shoppingoffice_supplies(notebooks, pens, scissors, ...)electronics(computer, printer, iPhone, cables, ...)cultural(books, movies, music, ...)groceries(food, cleaning, ...)other
- ✨ New categories:
- ⚡ ⚡ Significant Performance Improvement for Supplier Name Extraction on receipts:
We've also significantly boosted the accuracy of supplier_name extraction in the Receipt API. We've achieved a 30-to-50% error rate reduction by developing and training a novel, domain-specific NLP model.
⚡️ Features and Changes (April 7th, 2025)
- ✨ New field
document_type_extended.
This field provides more granular document classifications compared todocument_type. The possible output values are:CREDIT NOTE: Reduces the amount a buyer owes.INVOICE: Requests payment for goods or services.PAYSLIP: Details employee earnings and deductions.PURCHASE ORDER: Buyer's official request to purchase.QUOTE: Seller's estimated cost for goods or services.RECEIPT: Acknowledges payment.STATEMENT: Summary of financial transactions over a period.OTHER FINANCIAL: Miscellaneous financial documents.OTHER: Documents not fitting other financial categories.
- 🔥 Strong improvement on
currencyfield for invoices - ✨ Address decomposition into its’ sub-component:
street_number,street_name,po_box,address_complement,city,postal_code,state,countryfor invoices.
⚡️ Features and Changes (October 10th, 2024)
- 🐛 Fix
category/subcategoryconsistency for receipts. - 🐛 Fix French Guyana company IDs not correctly detected for invoices.
- 🐛 Fix text recognition errors for emails and websites for native PDFs for invoices.
- ✨ New field
po_number: The unique identifier which is issued by a buyer to a seller to authorize the purchase of goods or services. - ✨ New field
payment_date: The date by which the payment is expected or was made. - ✨ New sub-field
is_computedindue_date: It is set toTrueif thedue_dateis calculated based on payment terms or natural language, andFalseif it is directly specified as a date in the document.
⚡️ Features and Changes (July 17th, 2024)
We added the LiLT for line_items reconstruction for invoices on the the Financial document API.
- 🔥 Strong improvement on
line_itemsfor invoices.
Reduction in errors in terms of perfectly reconstructed lines of about 30 to 40%. - ⚡️ Strong reduction of processing time for invoices with many line items
- ✨ New field
unit_of_measureinline_itemsthat represents the unit of measurement for the item, such as kilograms, liters, units, etc.
⚡️ Features and Changes (July 11th, 2024)
We added the LiLT for total_amount, total_tax and taxes for invoices on the the Financial document API.
- 🔥 Strong improvement on
total_amount,total_taxandtaxes.
We have observed a reduction in error rates as follows:
- 36% for
total_amount - 25% for
total_tax(+7% on precision) - 15% for
taxes
⚡️ Features and Changes (June 12th, 2024)
- 🚀 Extended latin alphabet support for receipt
We released new models for our generic text detection and recognition pipeline. This release has increased the overall performances on all fields and supports extended latin alphabet characters:{'`', '¡', '¥', '¿', 'Á', 'Ã', 'Ä', 'Å', 'Æ', 'Ì', 'Í', 'Ð', 'Ñ', 'Ò', 'Ó', 'Õ', 'Ö', 'Ø', 'Ú', 'Ü', 'Ý', 'Þ', 'ß', 'á', 'ã', 'ä', 'å', 'æ', 'ì', 'í', 'ð', 'ñ', 'ò', 'ó', 'õ', 'ö', 'ø', 'ú', 'ü', 'ý', 'þ', 'Ā', 'ā', 'Ă', 'ă', 'Ą', 'ą', 'Ć', 'ć', 'Č', 'č', 'Ď', 'ď', 'Đ', 'đ', 'Ē', 'ē', 'Ė', 'ė', 'Ę', 'ę', 'Ě', 'ě', 'Ğ', 'ğ', 'Ģ', 'ģ', 'Ī', 'ī', 'Į', 'į', 'İ', 'ı', 'Ķ', 'ķ', 'Ĺ', 'ĺ', 'Ļ', 'ļ', 'Ľ', 'ľ', 'Ł', 'ł', 'Ń', 'ń', 'Ņ', 'ņ', 'Ň', 'ň', 'Ō', 'ō', 'Ő', 'ő', 'Ŕ', 'ŕ', 'Ŗ', 'ŗ', 'Ř', 'ř', 'Ś', 'ś', 'Ş', 'ş', 'Š', 'š', 'Ť', 'ť', 'Ū', 'ū', 'Ů', 'ů', 'Ű', 'ű', 'Ų', 'ų', 'Ź', 'ź', 'Ż', 'ż', 'Ž', 'ž', 'Ș', 'ș', 'Ț', 'ț', 'ẞ', '₿'} - 🔥 Strong improvement on
taxesfor multi-taxes extraction for receipt
The main focus of this release was to improve drastically the multi-taxes extraction.
We measured a decrease in error rates of 56% ontaxesfor multi-taxes extraction.
⚡️ Features and Changes (May 16th, 2024)
-
🔥 Strong improvement on
supplier_nameandsupplier_addressfor receipts
We measured a decrease in error rates for receipts of:- 27% for
supplier_name - 14% for
supplier_address
- 27% for
-
✨ New field:
receipt_numberanddocument_number
The API is now extracting thereceipt_numberreturned as a string. It also extracts thedocument_numberas a string, which is the document unique identifier. -
🐛 Fix date parsing for spanish/italian invoices
-
🐛 Fix reading errors for invoice number
-
🔥 Strong improvement on
document_typefor credit note / invoice classification -
⚡ Taxes from line items
taxesfield outputs taxes from the line items when no tax summary is present on the document.
⚡️ Features and Changes (April 25th, 2024)
-
🚀 Extended latin alphabet support for invoices
We released new models for our generic text detection and recognition pipeline. This release has increased the overall performances on all fields and supports extended latin alphabet characters:{'`', '¡', '¥', '¿', 'Á', 'Ã', 'Ä', 'Å', 'Æ', 'Ì', 'Í', 'Ð', 'Ñ', 'Ò', 'Ó', 'Õ', 'Ö', 'Ø', 'Ú', 'Ü', 'Ý', 'Þ', 'ß', 'á', 'ã', 'ä', 'å', 'æ', 'ì', 'í', 'ð', 'ñ', 'ò', 'ó', 'õ', 'ö', 'ø', 'ú', 'ü', 'ý', 'þ', 'Ā', 'ā', 'Ă', 'ă', 'Ą', 'ą', 'Ć', 'ć', 'Č', 'č', 'Ď', 'ď', 'Đ', 'đ', 'Ē', 'ē', 'Ė', 'ė', 'Ę', 'ę', 'Ě', 'ě', 'Ğ', 'ğ', 'Ģ', 'ģ', 'Ī', 'ī', 'Į', 'į', 'İ', 'ı', 'Ķ', 'ķ', 'Ĺ', 'ĺ', 'Ļ', 'ļ', 'Ľ', 'ľ', 'Ł', 'ł', 'Ń', 'ń', 'Ņ', 'ņ', 'Ň', 'ň', 'Ō', 'ō', 'Ő', 'ő', 'Ŕ', 'ŕ', 'Ŗ', 'ŗ', 'Ř', 'ř', 'Ś', 'ś', 'Ş', 'ş', 'Š', 'š', 'Ť', 'ť', 'Ū', 'ū', 'Ů', 'ů', 'Ű', 'ű', 'Ų', 'ų', 'Ź', 'ź', 'Ż', 'ż', 'Ž', 'ž', 'Ș', 'ș', 'Ț', 'ț', 'ẞ', '₿'} -
🔥 Strong improvement on
due_date,line_itemsfor invoices
We have observed a reduction in error rates as follows:- 20% for
due_date - 25% for
line_items
- 20% for
-
✨ New fields for invoices:
The API is now extracting the following fields:
customer_id: The identifier of the customer in the supplier’s referential. It can also refer to the client ID, client / customer account number…
supplier_phone_number: The phone number of the supplier
supplier_email: The supplier email address
supplier_website: The supplier website URL -
🔥 General accuracy improvement
Thanks to the improvement done on our generic text detection and recognition algorithms, we measured a reduction in error rates on all fields, especially for supplier and customer information. -
✨ New field for receipts:
Thelocalefield now contains the following subfields when the document sent to the endpoint is a receipt:
country: country code of the country where the receipt was issued (ex: US)
value: concatenation of language and country codes in ISO format (ex: en-US)
⚡️ Features and Changes (March 11th, 2024)
-
🚀 Integration of company ID & logo database for invoices
We have integrated a company ID database and a vector database featuring millions of logos. This enhancement enables our R&D team to efficiently rectify any issues with non-functional supplier names. -
🔥 Strong improvement on invoices for
supplier_name,customer_name, andinvoice_number
We have observed a reduction in error rates as follows:- 20% for
customer_name - 15% for
supplier_name - 10% for
invoice_number
The improvement in
supplier_namewas achieved by incorporating information from the databases. Thecustomer_namealgorithm now mirrors thesupplier_nameone.invoice_numbernow employs an NLP modality to boost its precision. - 20% for
⚡️ Features and Changes (January 30th, 2024)
- 🚀 Integration of a proprietary language model in the algorithm pipeline: LiLT
LILT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding.
LiLT's design combines textual content with layout structure. This means it doesn't just read the text but also understands how the text is organized within the document. For instance, it recognizes headings, paragraphs, tables, and other structural elements, which is a crucial aspect of context awareness in document processing.
The integration of this new language model in our pipeline helps us achieve better accuracy, and more flexibility when adding new supported fields. - 🔥 Strong improvement on
supplier_name,supplier_address, andsupplier_company_registrationson invoices
The main focus of this release was to improve drastically the supplier information extraction.
We measured a decrease in error rates of:- 42% for
**supplier_name** - 10% for
**supplier_address** - 10% for
**supplier_company_registrations**
Moreover, the integration of the LILT offers more robustness in terms of languages thanks to its language-independent component and will help us improve all other fields in the next releases.
- 42% for
- ✨ New field:
total_taxon invoices
The API is now extracting the total tax information, returned as a number. It corresponds to the total tax explicitly written in the document. - 🔥 General improvement for all fields on invoices
More training data was added to our training set, including different geographies and more variability. We’ve measured an improvement in accuracy for all extracted fields.
⚡️ Features and Changes (September 1st, 2023)
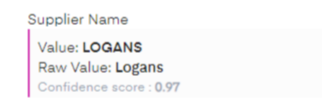
- New feature: Raw Value available for both Supplier Name and Customer Name. The Raw Value extracts the name without post processing nor formatting. It can thus be different from the Value.
⚡️ Features and Changes (May 23rd, 2023)
New extracted field:
- supplier_phone_number
Updated fields for receipts:
- supplier_address is now available for receipts
- supplier_company_registrations is now available for receipts
- line items is now available for receipts but limited to the following features: description, unit_price quantity, total_amount
⚡️Feature: First Release (January 17th, 2023)
Extracted fields:
- total_amount
- total_net
- taxes
- supplier_address
- supplier_name
- payment_details ( Null for receipt)
- orientation
- locale (currency, language)
- invoice_number (Null for receipt)
- reference_numbers ( Empty list for receipt)
- due_date
- document_type
- date
- customer_company_registration (Null for receipt)
- customer_address (Null for receipt)
- customer_name (Null for receipt)
- supplier_company_registration (Null for receipt)
- category
- Subcategory
- time (Null for Invoices)
- tip (Null for Invoices)
- total_tax (sum of taxes for Invoices)
- line_items (empty list for Receipt) :
product_code,description,quantity,unit_price,total_amount,tax_amount,tax_rate
Updated 10 days ago